Ollama
Cómo instalar y usar Ollama para correr LLMs en local: qué VRAM necesitas según el tamaño del modelo, comandos básicos, y cómo integrarlo con Python via REST o LangChain.
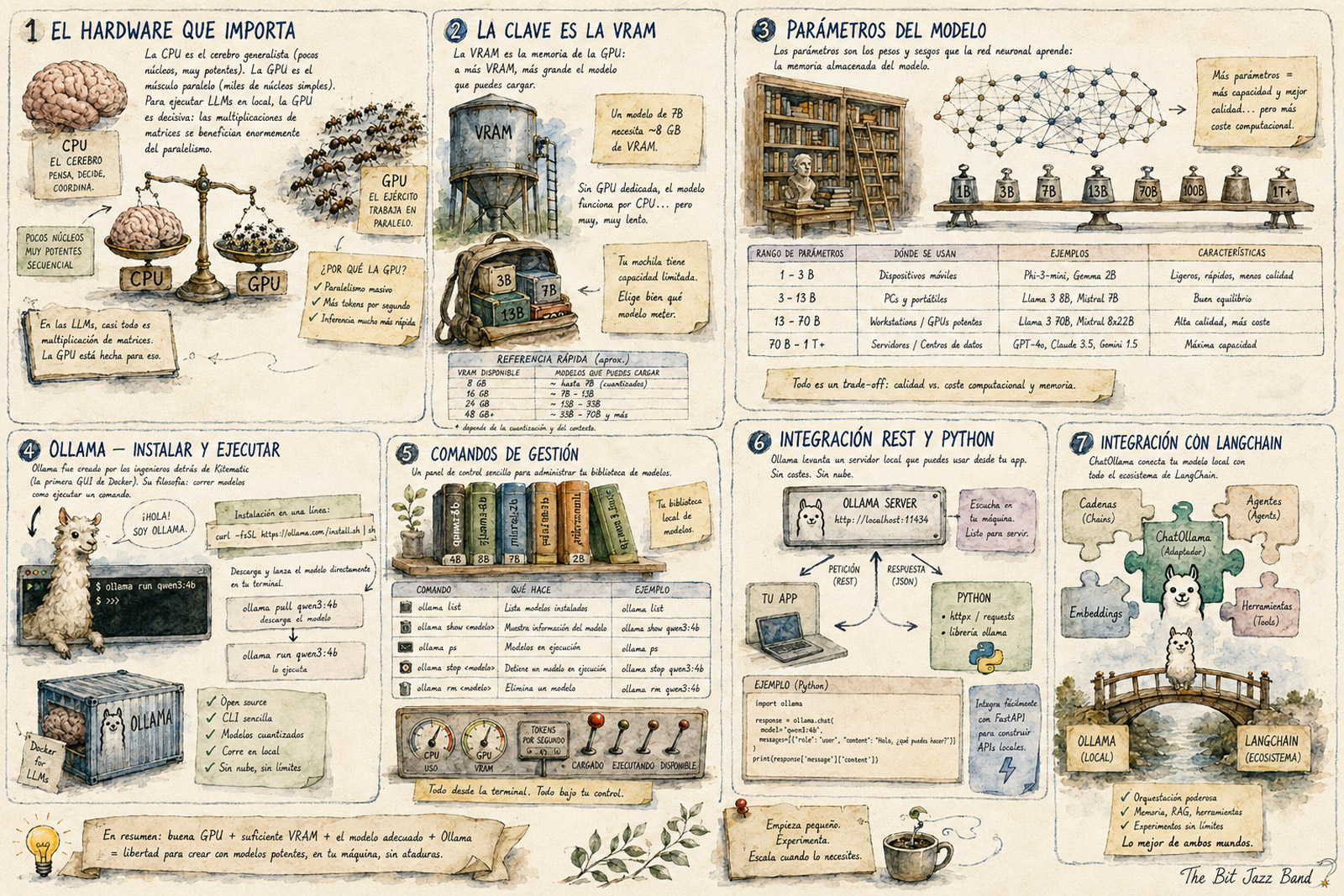
1. Algo de hardware
Ejecutar un modelo de lenguaje en local es más sencillo de lo que parece y puede ser útil en diferentes escenarios, como reducir costes de API, trabajar sin conexión, procesar documentos internos sin que salgan de tu infraestructura, o simplemente experimentar sin miedo a facturas inesperadas.
Dicho esto, puedes saltarte lo que queda de introducción si ya sabes cuál es la diferencia entre CPU y GPU y qué significan los parámetros de un modelo.
1.1. La clave es la VRAM
Pero antes que nada es importante tener en cuenta que el ordenador donde lo vamos a correr necesita cierta potencia, al menos si queremos trabajar con modelos que sean capaces de ir más allá del balbuceo. En este sentido, además de una CPU moderna y potente y, opcionalmente, un SSD para reducir los tiempos de carga, lo iimportante es contar con GPU dedicada para modelos más grandes de unos 16 GB de RAM.
Por si esto le sonara extraño a alguien, recuerdo que la CPU (Unidad Central de Procesamiento) y la GPU (Unidad de Procesamiento Gráfico) son los dos procesadores principales de un ordenador, aunque están diseñados para tareas muy distintas.
La CPU es el cerebro generalista. Tiene pocos núcleos (típicamente entre 4 y 32) pero muy potentes y están optimizados para ejecutar tareas complejas de forma secuencial. Es ideal para lógica, toma de decisiones, gestión del sistema operativo y aplicaciones generales.
Por el contrario, la GPU el músculo que trabaja en paralelo. Tiene miles de núcleos más pequeños y simples, diseñados para ejecutar miles de operaciones simples al mismo tiempo en paralelo. Nació para renderizar gráficos, pero hoy es fundamental en IA, ciencia de datos y minería de criptomonedas.
Cuando ejecutas un modelo de IA en local, las operaciones matemáticas que realiza (multiplicaciones de matrices enormes) se benefician enormemente del paralelismo de la GPU. Por eso con CPU el modelo funciona, pero es lento, procesa pocos tokens por segundo; pero, con GPU, puede generar texto mucho más rápido, incluso en tiempo real.
La clave es la VRAM, la memoria de la GPU. A más VRAM, más grande es el modelo que puedes cargar. Por ejemplo, para un modelo de 7B parámetros necesitas aproximadamente 8 GB de VRAM.
Veamos qué signifcan esos parámetros.
1.2. Parámetros de un modelo
Cuando se habla de un modelo de 7B parámetros, se está haciendo referencia a que es una una red neuronal con 7 mil millones (7 x 10⁹) de parámetros entrenables. Los parámetros son los pesos y sesgos de la red neuronal, básicamente los números que el modelo aprende durante el entrenamiento y que determinan cómo transforma una entrada en una salida. Son el equivalente a la memoria o el conocimiento almacenado del modelo.
Dicho de otra forma. El número de parámetros es un indicador aproximado de la capacidad de un modelo, cuánta información y patrones puede almacenar. Y, por lo tanto, son indicadores también de su rendimiento. Más parámetros suele significar mejor calidad de respuestas, aunque a veces también inervienen otros factores ahí. El trade-of es el coste computacional: más parámetros requiere más RAM/VRAM y más tiempo de inferencia.
Para que nos hagamos una idea, esta podría ser una equivalencia aproximada.
| Tamaño | Ejemplos | Uso típico |
|---|---|---|
| ~1-3B | Phi-3 Mini, Qwen2-1.5B | Dispositivos móviles, edge |
| ~7B | Mistral 7B, LLaMA 3.1 8B | PCs con GPU, servidores ligeros |
| ~13-30B | LLaMA 2 13B, Mixtral | Servidores medianos |
| ~70B+ | LLaMA 3 70B, Qwen2 72B | Servidores potentes |
| ~100B-1T+ | GPT-4, Gemini Ultra | Centros de datos |
Los modelos que instalemos, por lo tanto, dependerán de la capacidad de nuestras máquinas, pero es muy probable que nos sirva cualquiera en el rango de 3B-7B parámetros. Un modelo de 7B puede correr en una GPU con 10-16 GB de VRAM con calidad razonablemente buena para muchas tareas.
Vamos ya con el software. Hay un montón y medio de herramientas para trabajar con modelos en local, como LM Studio, que es una herramienta de trabajo todo en uno para ejecutar GPT4All, que está enfocado en soporte amplio de hardware y funciona incluso en máquinas modestas; Open WebUI, que permite montar una interfaz web tipo ChatGPT; vLLM, que es un motor de inferencia de código abierto para escenarios a escala de producción; o AnythingLLM, una plataforma muy potente.
En este tutorial me centraré en Ollama, que es perfecto para empezar. Descarga, gestiona y ejecuta LLMs directamente en el ordenador. Es de código abierto, crea un entorno aislado con todos los componentes del modelo (pesos, configuraciones y dependencias), y es compatible con macOS, Linux y Windows.
2. Hola mundo
Ollama fue fundado por Jeffrey Morgan y Michael Chiang en Palo Alto, California. Los dos venían de haber cofundado Kitematic, que fue la primera interfaz gráfica para Docker y se terminó por convertir en lo que hoy se conoce como Docker Desktop. Con esa experiencia en hacer herramientas complejas accesibles para desarrolladores, decidieron aplicar la misma filosofía al mundo de los LLMs y prepararon Ollama con el objetivo de que correr modelos de lenguaje localmente fuera tan sencillo como ejecutar un comando en la terminal, sin depender de la nube. Tal y como vamos a ver, sin duda que lo consiguieron.
La instalación es muy sencilla. En Windows tenemos dos opciones:
a. Con el instalador gráfico: descargamos el .exe desde ollama.com/download, lo ejecutamos y pulsamos el siguiente como si no hubiera un mañana.
O directamente desde PowerShell:
irm https://ollama.com/install.ps1 | iexEn Mac el proceso es idéntico. En Linux basta con ejecutar en la terminal:
curl -fsSL https://ollama.com/install.sh | shPara comprobar que todo funciona, abre una terminal y ejecuta:
ollama --versionSi devuelve un número de versión, está listo.
Una vez instalado, para descargar cualquier modelo hay que ejecutar por consola
ollama pull [:NOMBRE-DEL-MODELO]Y para ejecutarlo (y descargarlo si no está).
ollama run [:NOMBRE-DEL-MODELO]Por ejemplo, para empezar, podemos instalar qwen3:4b, un modelo chino de Alibaba, pequeño (4B), de última generación con capacidad de razonamiento, ideal para correr localmente.
ollama run qwen3:4bCuando termine la instalación, parecerá un prompt interactivo donde puedes escribirle directamente. Para salir, escribe /bye.

Además, ya estará disponible en la interfaz gráfica de Ollama.
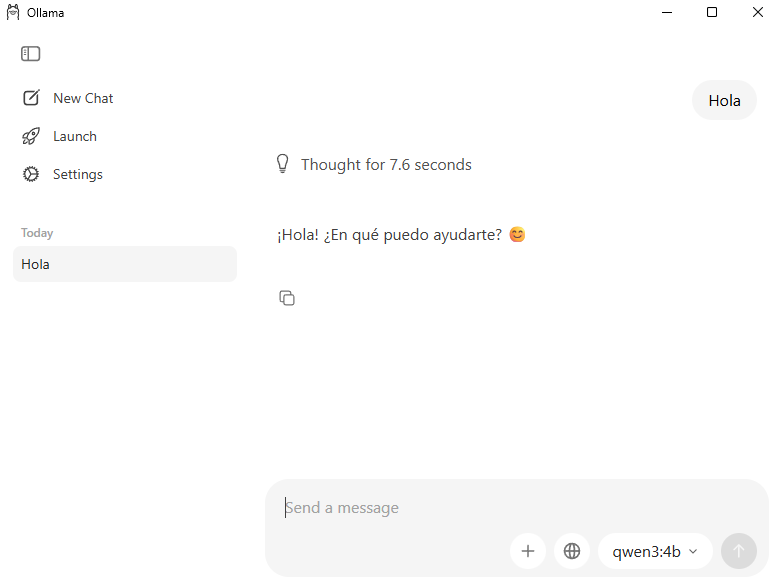
Y para buscar modelos disponibles, (directamente en la web)[ollama.com/library]
Otros comandos útiles son:
ollama list # modelos descargados
ollama show qwen3:4b # info del modelo (parámetros, tamaño, familia...)
ollama ps # modelos corriendo en este momento
ollama stop qwen3:4b # para un modelo que esté corriendo
ollama rm qwen3:4b # elimina un modelo3. Integración REST
Una de las utilidades de tener un llm en local es poder atacarlo vía REST para hacer pruebas en desarollo o lo que sea sin necesidad de dejarse una barbaridad de dinero trabajando contra un modelo potente de Anthropic, OpenAI y compañía.
Y es que Ollama levanta un servidor en http://localhost:11434, por lo que se puede llamar directamente desde FastAPI con httpx o requests:
from fastapi import FastAPI
import httpx
app = FastAPI()
@app.post("/chat")
async def chat(mensaje: str):
async with httpx.AsyncClient() as client:
response = await client.post(
"http://localhost:11434/api/chat",
json={
"model": "qwen3:4b",
"messages": [{"role": "user", "content": mensaje}],
"stream": False
},
timeout=60
)
return response.json()["message"]["content"] También podríamos hacerlo, más elegante, mediante la librería oficial de Ollama.
Instalamos.
uv add ollamaEjemplo del endpoint.
from fastapi import FastAPI
import ollama
app = FastAPI()
@app.post("/chat")
async def chat(mensaje: str):
response = ollama.chat(
model="qwen3:4b",
messages=[{"role": "user", "content": mensaje}],
options={"think": False} # Importante para que no se quede pensando y devuelva la respuesta lo antes posible
)
return {"respuesta": response["message"]["content"]}Y para probarlo, con ollama y el server levantados.
from fastapi import FastAPI
import ollama
app = FastAPI()
@app.post("/chat")
async def chat(mensaje: str):
response = ollama.chat(
model="qwen3:4b",
messages=[{"role": "user", "content": mensaje}],
options={"think": False} # Importante para que no se quede pensando y devuelva la respuesta lo antes posible
)
return {"respuesta": response["message"]["content"]}4. Integración con Langchain
De hecho, también podríamos integrarlo con langChain.
Instalamos el tinglado
langchain-ollama langchain-coreY listo.
from langchain_ollama import ChatOllama
llm = ChatOllama(
model="qwen3:4b",
temperature=0.7,
)
response = llm.invoke("¿Qué es FastAPI?")
print(response.content)La librería tiene muchas más opciones, como la posibilidad de generar embeddings, pero me remito a la documentación oficial, que ahora sería desviarnos mucho del tema.
Otro día explico otras herramientas, de momento vamos a dejarlo aquí.